


Most model benchmarks measure abstract capabilities, but they are several steps removed from the work repairers perform every day. This benchmark focuses on the outcome that matters most in parts ordering: whether the final parts order was right and complete.
Performance is measured using historic accuracy, the share of completed repair jobs where the parts order contained the correct parts and all required parts. The benchmark consists of two separate evaluations:
- Interpreter in the real world, embedded within a repairer's workflow.
- Interpreter's Last Exam, which measures the model on its own without human input.
Together, these evaluations measure both real-world performance and the model's underlying capability.
Considerations and constraints
Benchmarking repair work is harder than scoring a model. Meaningful comparisons require careful controls.
- Damage severity: Vehicle repair jobs range from simple knocks to near-write-offs. The severity of the damage determines how many parts are required, how damage is investigated, and how the final parts list is produced. To make comparisons meaningful, performance is measured between similar categories of damage rather than across the full range of repair jobs.
- Teardown: Repair shops handle collision repairs differently. Some estimators partially disassemble the vehicle before producing a parts list, while others rely on external inspection. Teardown reveals hidden damage and produces a more accurate assessment of the vehicle, but it also adds time to the estimating process. The historic repair data used in this benchmark does not indicate whether teardown occurred. Because teardown materially affects the information available to the estimator, both evaluations are limited to small and medium damage repairs, where it is less influential.
Real world
The real-world benchmark measures Interpreter inside the workflow repairers already use.
The dataset consists of historic repair work completed by real repair businesses. Performance is measured by comparing parts orders produced with Interpreter against parts orders produced using the tools and processes repairers already work with.

Interpreter's Last Exam
Interpreter's Last Exam is named after Humanity's Last Exam, a benchmark designed to test the limits of frontier models.
In this evaluation, Interpreter operates independently without estimator input. The model receives vehicle information, photos, and damage context, then produces a parts list on its own.
The appropriate human comparison is a remote estimator. Remote estimators assess vehicles from photos and vehicle information without direct access to the vehicle, making this a comparable workflow. Because remote estimating is most common on small and medium damage repairs, the benchmark evaluates the same category of repair work.
General-purpose frontier models are included as a reference point.
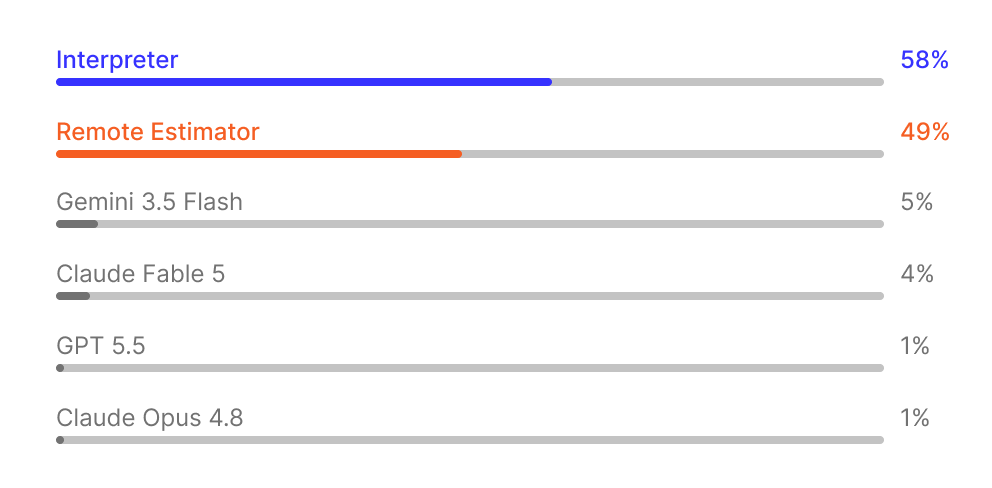
Score is measured using F1 to account for the tradeoff between coverage and precision. In parts estimation, a system can recommend more parts to improve coverage, but that can also create more incorrect recommendations. Human remote estimators tended to include more parts, while some models were more conservative. F1 balances both behaviors by measuring whether the required parts were found and whether the recommended parts were correct.








